Detección de anomalías
NORA observa el histórico de tus jobs y marca de forma automática las ejecuciones que se salen de lo normal. El objetivo es avisarte de degradaciones (un robot que de pronto tarda el doble, o un proceso que empieza a fallar más de lo habitual) sin que tengas que vigilar los paneles manualmente.
La detección de anomalías es una función de plan: está disponible en Pro y Enterprise, y no en Starter. Si el plan del tenant no la incluye, las rutas de la API responden con un error de funcionalidad no habilitada.
Qué detecta NORA
Sección titulada «Qué detecta NORA»Actualmente NORA ejecuta dos detectores. Ambos trabajan por proceso y por tenant, y solo consideran procesos con suficiente historial.
Tipo (type) | Qué busca | Cómo lo decide |
|---|---|---|
duration_spike | Un job que tardó mucho más de lo habitual para su proceso | z-score de la duración frente a la media de los últimos 30 días |
error_rate_spike | Un proceso cuya tasa de error subió respecto a la semana anterior | comparación de tasa de error semana actual vs. semana previa |
Anomalías de duración (z-score)
Sección titulada «Anomalías de duración (z-score)»Para cada proceso, NORA calcula la media y la desviación estándar de la duración (finished_at − started_at) de los jobs completados en los últimos 30 días. Para construir esa línea base se exigen al menos 5 jobs completados (MIN_SAMPLES); los procesos con menos historial se ignoran.
Luego revisa los jobs completados en la última hora y calcula su z-score:
z = (duración_del_job − media) / desviación_estándarSi z > 2.0 (DEVIATION_THRESHOLD), el job se marca como anomalía. La severidad depende de cuán lejos quede de lo normal:
warningcuando2.0 < z < 3.0criticalcuandoz >= 3.0
Los jobs cuyo proceso tiene desviación estándar 0 (duraciones siempre idénticas) no se evalúan, para evitar divisiones inválidas. Tampoco se vuelve a marcar un job que ya tenga una anomalía duration_spike.
Anomalías de tasa de error (semana vs. semana)
Sección titulada «Anomalías de tasa de error (semana vs. semana)»Este detector compara, por proceso, la tasa de error de los últimos 7 días contra la de los 7 días anteriores, contando solo jobs en estado completed o failed y exigiendo al menos 5 jobs (MIN_SAMPLES) en cada ventana.
Se genera una anomalía error_rate_spike cuando:
- la tasa actual supera a la histórica en más de 20 puntos (
ERROR_RATE_THRESHOLD = 0.20), y - la tasa actual es mayor al 10 %.
La severidad es warning si la tasa actual es menor al 50 %, y critical si la iguala o supera. Como con la duración, no se duplican anomalías ya registradas para ese proceso en la misma semana.
Cómo funciona a alto nivel
Sección titulada «Cómo funciona a alto nivel»La detección corre en segundo plano dentro del backend, en un bucle que se ejecuta cada hora (ANOMALY_INTERVAL = 3600). Para que solo un proceso la ejecute en despliegues con varias réplicas, toma un lock distribuido (anomaly_detection) antes de cada pasada.
flowchart TD
A[Bucle horario] --> B{Lock distribuido<br/>disponible?}
B -- no --> A
B -- si --> C[Calcular linea base<br/>por proceso 30 dias]
C --> D[Revisar jobs recientes]
D --> E{z-score mayor a 2<br/>o tasa de error +20pp?}
E -- no --> A
E -- si --> F[Crear registro Anomaly]
F --> G{severity = critical?}
G -- si --> H[Enviar notificacion]
G -- no --> A
H --> A
Cuando se detectan anomalías de duración críticas, NORA dispara una notificación por los canales configurados del tenant, reutilizando el evento job_failed con el job_id y el mensaje de la anomalía. Las anomalías de tipo warning se registran pero no notifican.
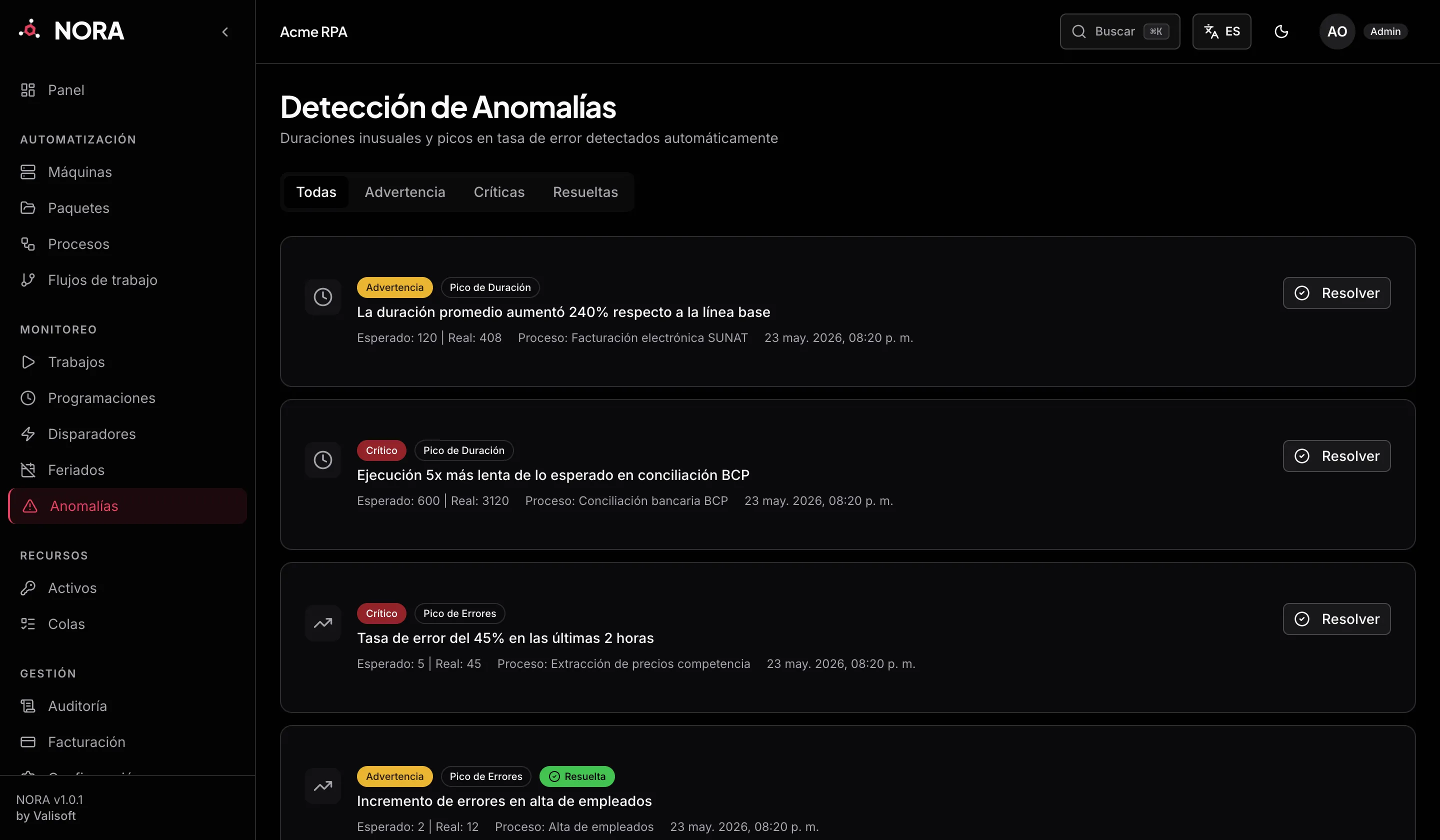
Consultar y resolver anomalías
Sección titulada «Consultar y resolver anomalías»Las anomalías se exponen en la API bajo el prefijo /api/v1/anomalies. Estas rutas forman parte del panel y usan la sesión autenticada del usuario; no se invocan con X-API-Key. El acceso requiere rol admin, operator o viewer para consultarlas, y admin u operator para resolverlas.
Listar anomalías
Sección titulada «Listar anomalías»GET /api/v1/anomalies?page=1&limit=20&severity=critical&is_resolved=falseParámetros de consulta:
| Parámetro | Tipo | Por defecto | Descripción |
|---|---|---|---|
page | entero ≥ 1 | 1 | Página de resultados |
limit | entero 1–100 | 20 | Elementos por página |
severity | string | — | Filtra por info, warning o critical |
is_resolved | booleano | — | Filtra por estado de resolución |
La respuesta es paginada (data + meta):
{ "success": true, "data": [ { "id": "f1e2d3c4-0000-0000-0000-000000000000", "type": "duration_spike", "severity": "critical", "process_id": "a1b2c3d4-0000-0000-0000-000000000000", "job_id": "9f8e7d6c-0000-0000-0000-000000000000", "message": "Job tardo 412s (promedio: 95s, desvio: 4.2σ)", "expected_value": 95.0, "actual_value": 412.0, "is_resolved": false, "created_at": "2026-06-19T14:03:11+00:00" } ], "meta": { "page": 1, "limit": 20, "total": 1, "pages": 1 }}Los campos expected_value y actual_value son numéricos: para duration_spike representan segundos (promedio y duración real); para error_rate_spike representan porcentajes (tasa histórica y tasa actual).
Marcar una anomalía como resuelta
Sección titulada «Marcar una anomalía como resuelta»PATCH /api/v1/anomalies/{anomaly_id}/resolveMarca la anomalía como resuelta (is_resolved = true). Cada tenant solo ve y resuelve sus propias anomalías.
{ "success": true, "data": { "id": "f1e2d3c4-0000-0000-0000-000000000000", "is_resolved": true }}Buenas prácticas
Sección titulada «Buenas prácticas»- Mantén un historial sano: la línea base necesita al menos 5 ejecuciones completadas por proceso en 30 días; los procesos nuevos no generan anomalías de duración hasta acumular muestras.
- Configura los canales de notificación del tenant para enterarte de las anomalías críticas en cuanto ocurren.
- Revisa periódicamente las anomalías
warning: no notifican, pero suelen anticipar una degradación antes de que se vuelva crítica.